BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic
By A Mystery Man Writer
Description

BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic

PDF) Prune Once for All: Sparse Pre-Trained Language Models

Poor Man's BERT - Exploring layer pruning

PDF) The Optimal BERT Surgeon: Scalable and Accurate Second-Order Pruning for Large Language Models

PDF) Prune Once for All: Sparse Pre-Trained Language Models
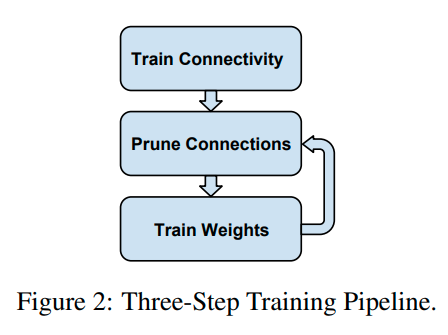
Neural Network Pruning Explained
Latest MLPerf™ Inference v3.1 Results Show 50X Faster AI Inference for x86 and ARM from Neural Magic - Neural Magic

PDF) The Optimal BERT Surgeon: Scalable and Accurate Second-Order Pruning for Large Language Models

Guy Boudoukh - CatalyzeX
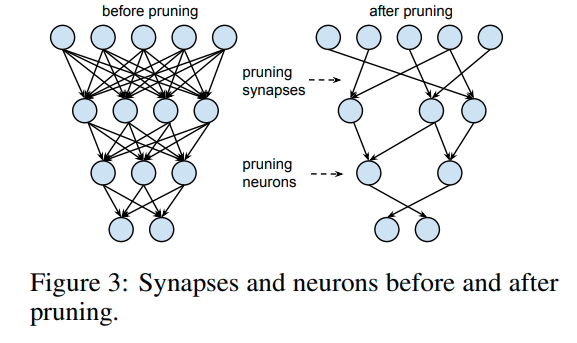
Neural Network Pruning Explained

arxiv-sanity

PDF) oBERTa: Improving Sparse Transfer Learning via improved initialization, distillation, and pruning regimes
from
per adult (price varies by group size)







